Learning Non-Lambertian Object Intrinsics across ShapeNet Categories
- Jian Shi1,2
- Yue Dong2
- Hao Su3
- Stella X. Yu4
- 1University of Chinese Academy of Sciences
- 2Microsoft Research
- 3Stanford University
- 3UC Berkeley / ICSI
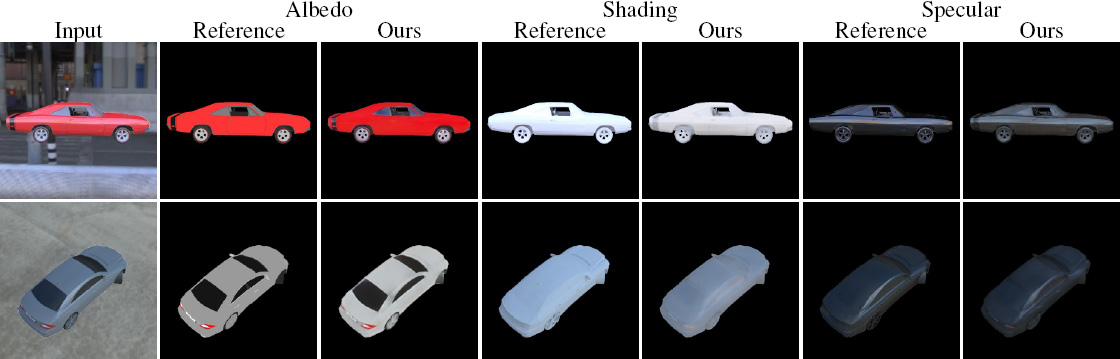
Intrinsic decomposition results validated with ground truth.
Abstract
We consider the non-Lambertian object intrinsic problem
of recovering diffuse albedo, shading, and specular
highlights from a single image of an object.
We build a large-scale object intrinsics database based
on existing 3D models in the ShapeNet database. Rendered
with realistic environment maps, millions of synthetic
images of objects and their corresponding albedo, shading,
and specular ground-truth images are used to train an
encoder-decoder CNN. Once trained, the network can decompose
an image into the product of albedo and shading
components, along with an additive specular component.
Our CNN delivers accurate and sharp results in this
classical inverse problem of computer vision, sharp details
attributed to skip layer connections at corresponding resolutions
from the encoder to the decoder. Benchmarked on
our ShapeNet and MIT intrinsics datasets, our model consistently
outperforms the state-of-the-art by a large margin.
We train and test our CNN on different object categories.
Perhaps surprising especially from the CNN classification
perspective, our intrinsics CNN generalizes very
well across categories. Our analysis shows that feature
learning at the encoder stage is more crucial for developing
a universal representation across categories.
We apply our synthetic data trained model to images and
videos downloaded from the internet, and observe robust
and realistic intrinsics results. Quality non-Lambertian intrinsics
could open up many interesting applications such
as image-based albedo and specular editing.
KeywordsIntrinsic image decomposition, Deep learning |
Downloads |